The screenshot here is our company Trello board, where we manage our product roadmap. We are extremely lucky in that our thousands of happy customers give us a steady stream of suggestions for new features and improvements, which we used to just throw on this board.
However, that soon lead to stagnation, and I would become paralysed with indecision whenever I looked at the board. It all seemed too much, and overwhelming and I never knew where to begin, or to stop.
How did we solve this? I mean, we still had to capture our customer’s wishes, but it was leading to a literal wall of things to do, and the more we added to that wall, the less chance there was of things happening.
Here is what we did.
Step one was to basically stop the development team from looking at this board at all. And that includes myself.
Step two was to get our Customer Success team to start managing the cards on the board, and to do it in a deliberate and disciplined manner. After all, the CS team were the ones talking to the customers during sales, onboarding and training calls, so they were at the ‘coal face’ as it were, and knew the exact challenges that our customers were facing.
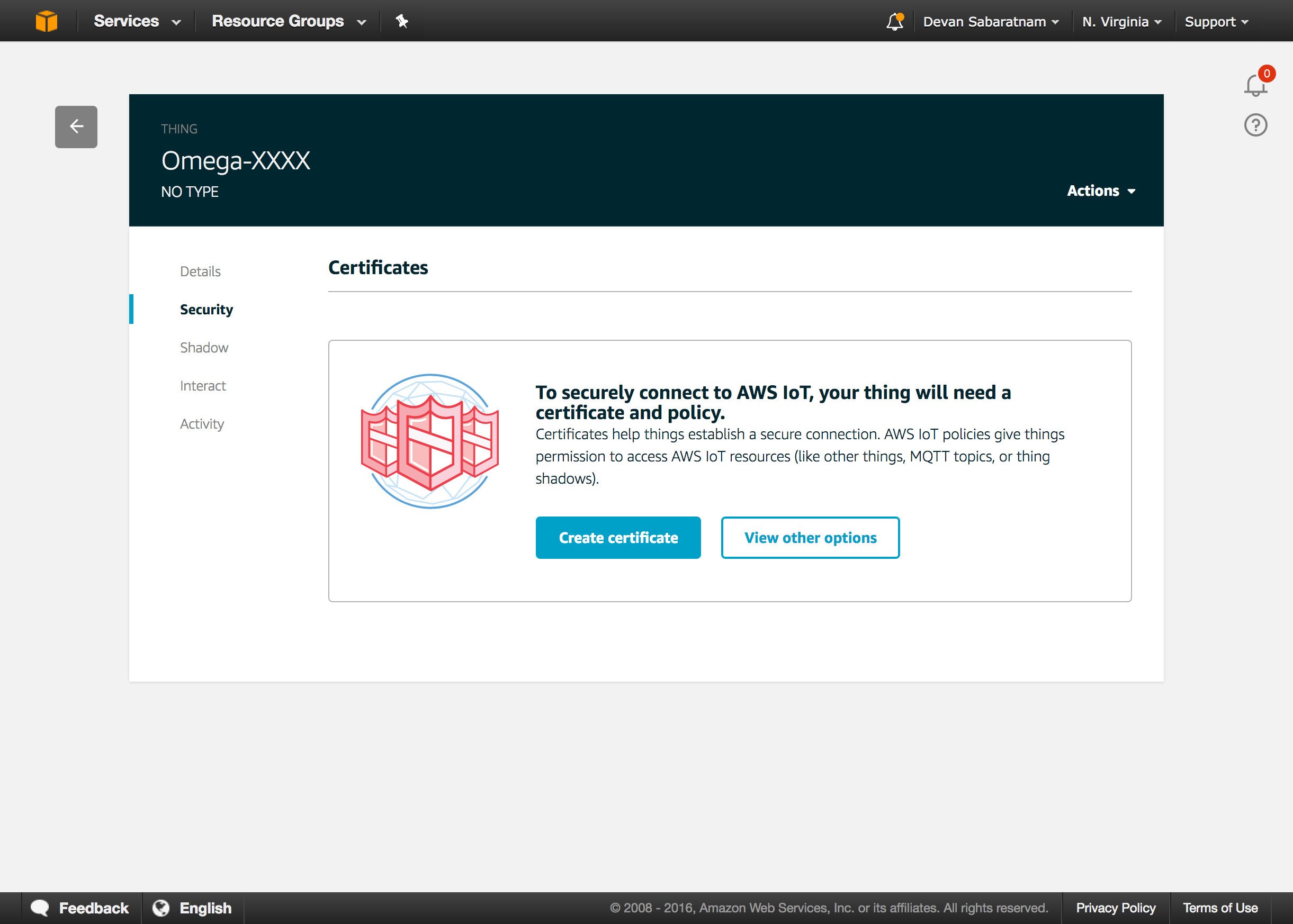
The first thing we did, was to split the board into three logical sections. The left section is where incoming cards go to be evaluated and prioritised. The middle section was for recording progress, and the right hand section was for long term ‘back burner’ tasks.
Our current column layouts across the screen are:
New - To Triage
To Discuss
Scoping
Planned (Next 3 Months)
Doing
Done (Customer to be advised)
Done (Completed)
On Hold
UX Improvements
Column for each module in our app, i.e. Leave Management, E-Signatures
Cards pretty much move from left to right on here. Let me explain how.
The leftmost column is our ‘Triage’ column. Any new suggestions, comments or bug reports will go in here first, without any judgement or pre-conceptions. It is a column to ‘brain dump’ anything that comes through our support ticketing system or direct emails to CS team members.
It is important to note that any items the CS team adds as a result of a customer issue or request, all have a link to the relevant ticket in our HelpScout support ticketing system so we can cross refer back to the original conversation.
Once a week or so, the CS team will get together and go through this Triage column. They will decide what requests are important or critical, as well as see if any of the new cards are duplicates of older requests.
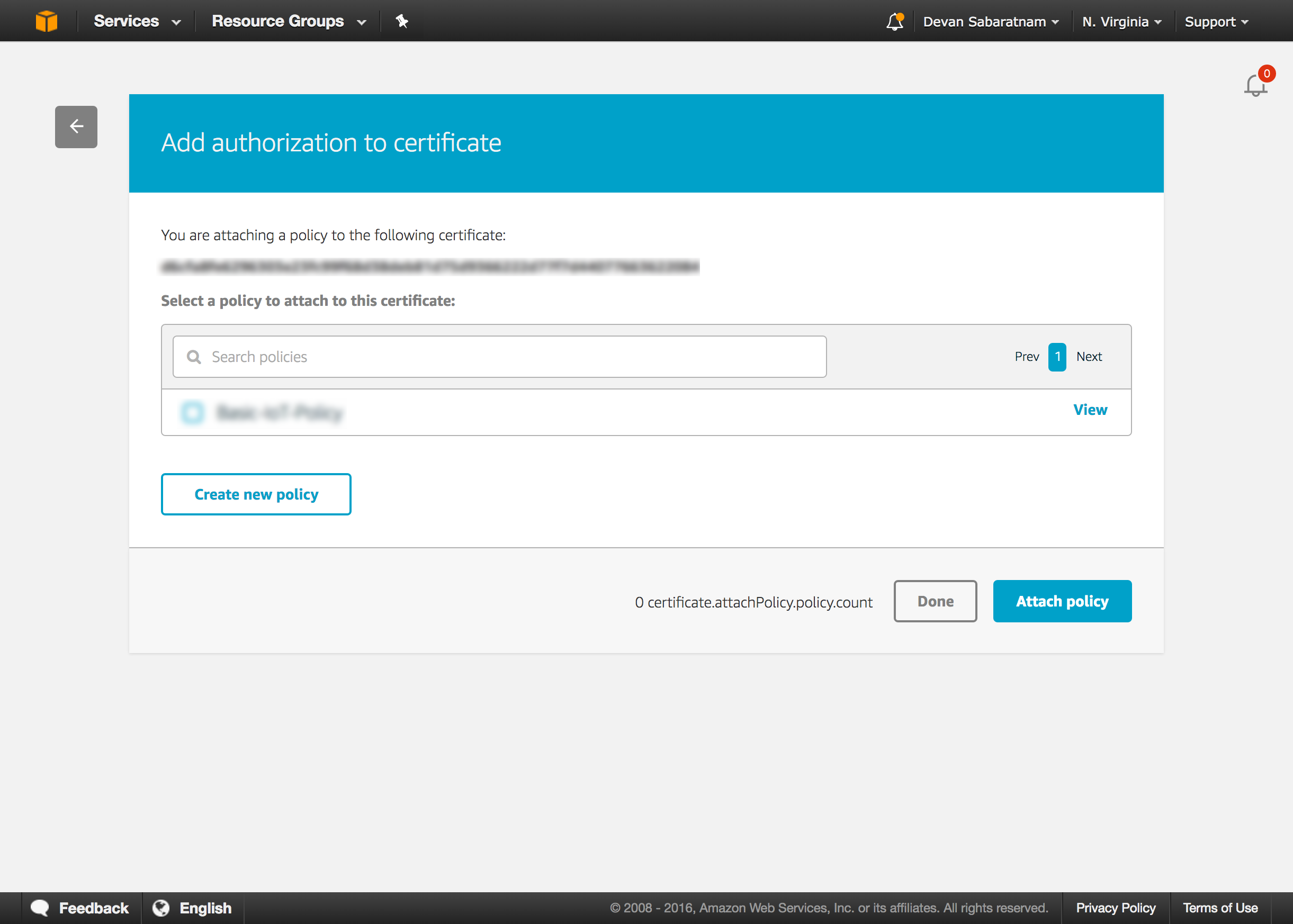
Things that they decide will be worked on will be moved into the next column, which is called ‘Scoping’. This column has a set process of itself, in order to scope out exactly what changes will be required in our system. The task has to pass scrutiny around security changes to our app, demand from other users, training and documentation required etc. A copy of the steps that a card in scoping has to go through is listed below:
Description
[briefly describe what the feature or fix should do]
Owner
[who is the owner of this story, who will be managing it moving forward]
Audience
[ ] Admin User [ ] Employee
Problem Space
[describe the problem or roadblock that this feature/fix will be solving. Are there any workarounds within HR Partner now, or are customers hacking around with existing functionality to try and accomplish their goals?]
Expected Outcomes
[describe what the final outcome or goal of this feature or fix will be. Try and go into details of the business problem that the end user will be solving]
Priority
[ ] Urgent [ ] High [ ] Medium [ ] Low [ ] Wishlist
Workflow
[what is the expected sequence of steps that the end user will have to go through in order to achieve their goals using this feature/fix? If there are multiple steps to prepare something, then process it, try and show a flowchart if possible]
Data Changes
[does this feature or fix make major changes to any data? Does it perform mass deletions or bulk modification of existing data that the user should be aware of? Should there be a way to reverse it if things go wrong?]
Permissions
[describe the permission restrictions needed on this feature or fix. Does it have to be restricted to employees in a particular Department or Location, should some employees be excluded from it based on any criteria etc.]
Interface
[does the interface need to be modified to suit this new feature or fix? If so, will it need a new menu or new screens created, or does it need a modification to existing menus or screens?]
Notifications
[what sort of notifications will be required for the end user? Will there be emails that need to be generated and sent to admin users or employees? Will any internal in app notifications need to be generated to let people know something has happened?]
External Factors
[does this feature rely on external tools, such as Slack or our API in order to be successfully used?]
Mockups
[try and include mockups or prototypes of any screens or workflows. Hand drawn, scanned/photographed and uploaded is fine, or sketches with any rudimentary drawing tool, or Photoshop, Figma, Sketch etc.]
Once the scoping process is completed, a decision is made as to whether the work will be done now, or at a later date.
This is when the card gets moved to either our Planned column or the Doing column.
At this point, the development team lead (myself) gets involved again. I look at the cards in these two columns, and set the priority from top to bottom. Now comes the time to take it to the next level.
We use a system called Phabricator for our development repository tracking, code reviews and bug ticket handling. Phabricator was originally developed internally at Facebook before being spun out on its own. Some people find it too technical, but I’ve used it for years and love it (even though the development company in charge has shuttered and stopped working on it as of August 2021).
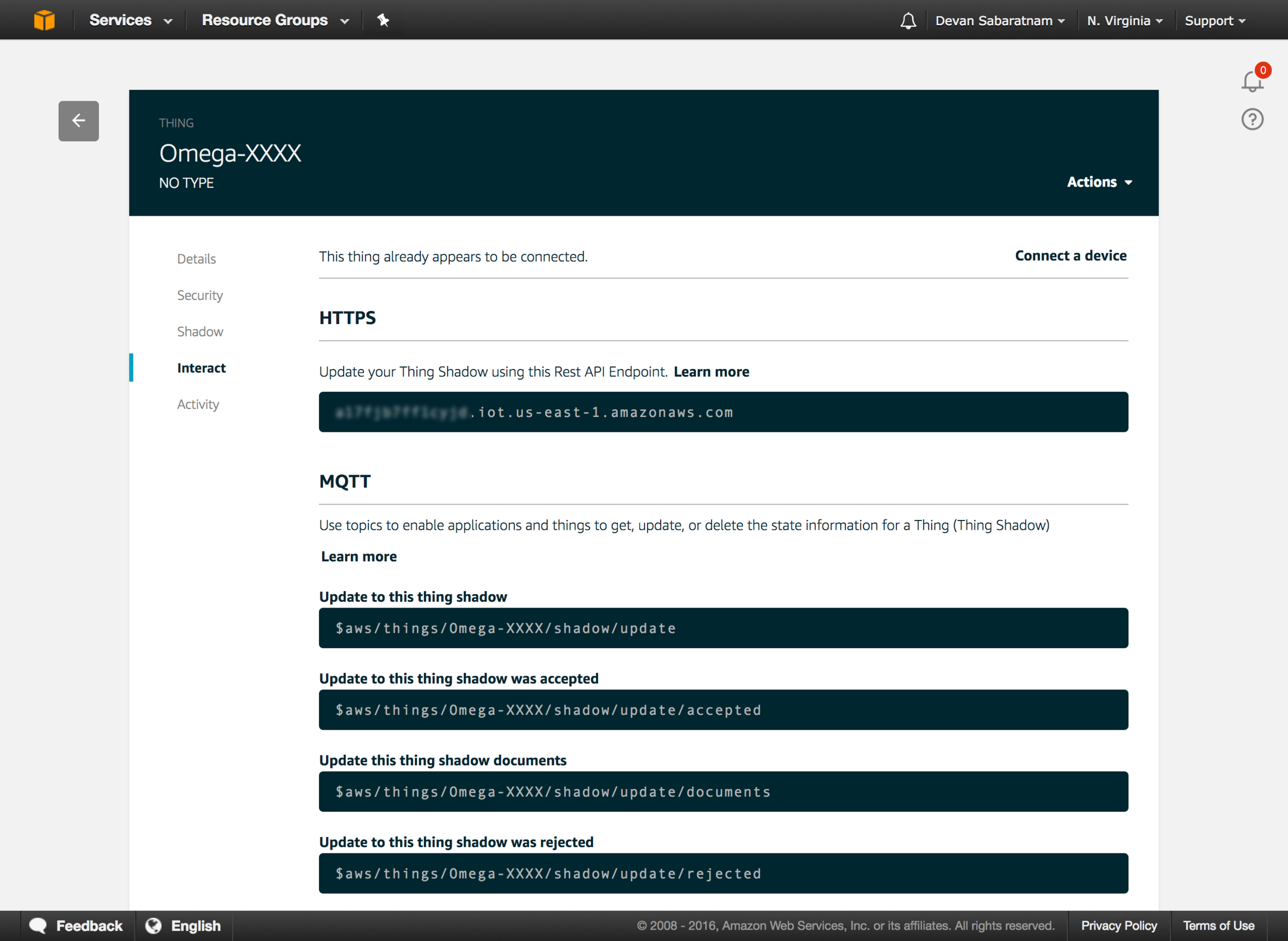
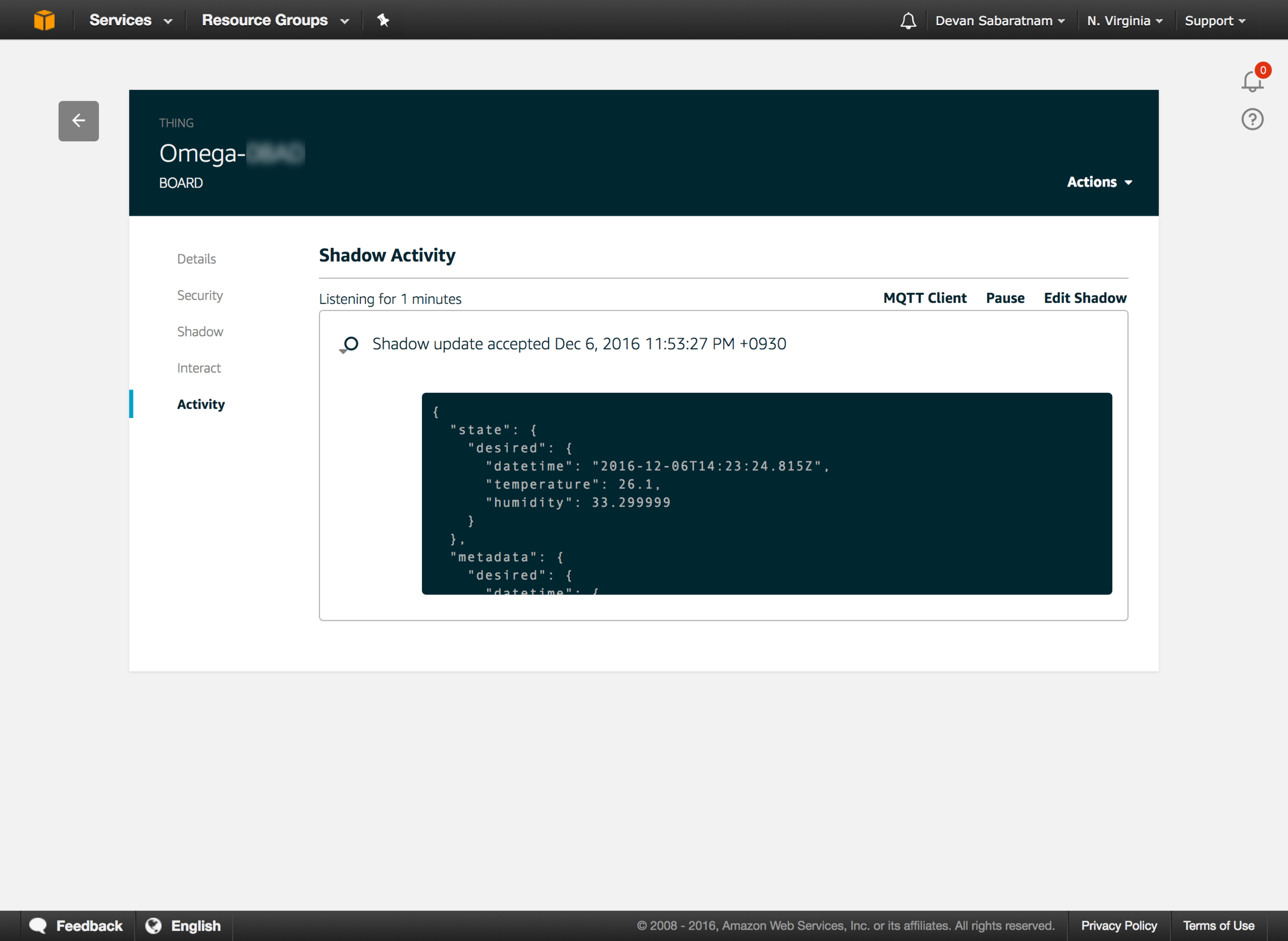
When a card is to be worked on, I create a ticket in Phabricator and assign it to the developer that I want to be in charge of the ticket. Within the Phabricator ticket, I paste the link to the Trello card, and on the Trello card, I enter the Phabricator ticket number as a cross referencing mechanism.

The Phabricator ticket reference in the Trello card.

Showing the Trello link in the Phabricator ticket.
This means that the CS team can dive into Phabricator and find the work progress status if needed, and the development team can also go back to Trello and see the customer support tickets relating to the task at hand.
This two way deep dive (and yes, all our team have access to all our systems as a default) is invaluable to us keeping track of the status of any work being done.
My main focus is keeping these tickets on track in our Phabricator system. Once the tickets are completed, and tested on our staging server, then they are closed in Phabricator, and the developer responsible for the ticket will have to go back to Trello and either move the card to the Done column, or if there are links to our support ticketing system on the card, then it is moved to the Done - Customer to be advised column.
The CS team will then, as part of their Trello maintenance routine, go through the cards on Done - Customer to be advices and send responses to our customers advising them that the bug has been fixed, or the feature they requested has been implemented.
This I think is the biggest shining light of our process - Our customer is kept in the loop from initial support ticket right up to the job being done and pushed to production.
At our current team size, this process seems to work really well for us. It will be interesting to see how it scales as we grow. We will probably need to look at other toolsets and integrations, seeing as how Phabricator is now end of life.
Would love to hear from other startups how you handle a complex and busy roadmap. Drop us a comment below.